

OpenAI가 2019년에 GPT-2를 발표했다.
GPT-1과의 가장 핵심적인 차이는 GPT-1는 Fine-Tuning이 필수적이었던 반면, GPT-2부터는 Zero-shot 수행이 가능하게 됐다는 점이다. 파라미터 수도 1.17억 개에서 15억 개로 10배 이상 증가했다. 구조적으로도 큰 차이가 있는데:
- GPT-1: 인풋 -> 어텐션 -> Add -> Norm
- GPT-2: 인풋 -> Norm -> 어텐션 -> Add
요렇게 Layer Norm을 앞으로 가져왔다는 것이다. (마지막 self-attention 블록 뒤에 Norm을 하나 더 추가하기도 했다.) 정규화는 초장에 해놓고 다음 블록으로 뱉는 값에 정규화를 하지 않았기 때문에 신호가 뒷부분까지 더 잘 전달됐다. (GPT-1은 레이어가 12개였는데 GPT-2는 레이어가 48개라서 뒤쪽까지 데이터가 잘 전달되는 게 더더욱 중요해졌다.)
참고로 Batch Norm이 아니라 Layer Norm을 한 이유는, 전자의 경우 배치 단위로 평균과 분산을 구하는데 자연어는 문장마다 길이가 제각각이라서 굳이 이렇게 할 필요가 없었기 때문이다.
학습한 데이터 성격도 GPT-1이 책 위주였다면 GPT-2는 미국의 디씨라 불리는(그 반대인가? ㅇㅅㅇ) 레딧의 텍스트도 긁어오고 뉴스, 블로그, 코드 등 다양한 데이터를 긁어왔다는 점이다.

물론 현재 시점에서 보자면 sLLM 축에도 끼지 못하는 커여운 크기다.
암튼 우리는 이걸 적당히 fine-tuning 해보도록 하자!
https://github.com/PhamPham2S/self-study/tree/main/GPT_fine-tuning
self-study/GPT_fine-tuning at main · PhamPham2S/self-study
Contribute to PhamPham2S/self-study development by creating an account on GitHub.
github.com
# 1. 필수 라이브러리 설치
# (Colab 세션이 새로 시작될 때마다 설치해야 합니다)
!pip install -q transformers datasets accelerate pandas
import os
import pandas as pd
from datasets import load_dataset
from google.colab import drive
# 2. 구글 드라이브 마운트 (창고 연결)
print("🔑 구글 드라이브 연결 중...")
drive.mount('/content/drive')
코랩으로 할 거임

# 3. 프로젝트 경로 설정 (구글 드라이브 내 폴더)
# 이 경로에 데이터와 나중에 만들 모델이 저장됩니다.
project_path = '/content/drive/MyDrive/News_Summary_Project'
data_file_path = os.path.join(project_path, 'news_train.csv')
# 폴더가 없으면 생성
if not os.path.exists(project_path):
os.makedirs(project_path)
print(f"📂 드라이브에 새 폴더 생성 완료: {project_path}")
else:
print(f"📂 드라이브 폴더 확인 완료: {project_path}")
경로도 설정한다.

# 4. 데이터 로드 로직 (있으면 읽고, 없으면 다운로드)
if os.path.exists(data_file_path):
print(f"\n⚡ 드라이브에 저장된 데이터가 있습니다. 바로 불러옵니다.")
economy_df = pd.read_csv(data_file_path)
else:
print(f"\n⬇️ 저장된 데이터가 없습니다. 새로 다운로드하고 정제합니다...")
# 데이터셋 다운로드 (daekeun-ml/naver-news-summarization-ko)
try:
dataset = load_dataset("daekeun-ml/naver-news-summarization-ko")
full_df = pd.DataFrame(dataset['train'])
# 'economy' 또는 '경제' 카테고리 필터링 (10,000개 샘플링)
# 데이터셋 컬럼 확인 후 필터링
if 'category' in full_df.columns:
# 카테고리가 'economy' 혹은 '경제'인 것 찾기
target_category = ['economy', '경제']
economy_df = full_df[full_df['category'].isin(target_category)].sample(n=10000, random_state=42)
else:
# 카테고리가 없으면 전체에서 랜덤 추출
print("⚠️ 카테고리 정보 없음. 전체에서 랜덤 추출합니다.")
economy_df = full_df.sample(n=10000, random_state=42)
# 드라이브에 CSV로 영구 저장
economy_df.to_csv(data_file_path, index=False)
print(f"✅ 데이터 정제 후 드라이브에 저장 완료: {data_file_path}")
except Exception as e:
print(f"❌ 데이터 다운로드 실패: {e}")
raise e
이제 데이터를 읽어온다.


요걸 가져올 거다. 날짜, 카테고리, 언론사, 제목, 링크, 요약이 있다. 경제 카테고리만 가져오자!
# 5. 최종 데이터 확인
print("\n--- 👀 데이터 확인 (상위 1개) ---")
print(f"제목: {economy_df.iloc[0]['title']}")
print(f"요약: {economy_df.iloc[0]['summary']}")
print(f"데이터 개수: {len(economy_df)}개")
10,000개가 불러와졌다.

이제 데이터를 가져올 거다.
from transformers import PreTrainedTokenizerFast
from torch.utils.data import Dataset, DataLoader
from sklearn.model_selection import train_test_split
import torch
# 1. 토크나이저 로드 (SKT KoGPT2)
# bos(문장시작), eos(문장끝), unk(모름), pad(길이맞춤), mask(가림) 토큰을 명시합니다.
tokenizer = PreTrainedTokenizerFast.from_pretrained(
"skt/kogpt2-base-v2",
bos_token='</s>',
eos_token='</s>',
unk_token='<unk>',
pad_token='<pad>',
mask_token='<mask>'
)
print(f"✅ 토크나이저 로드 완료! (단어 집합 크기: {len(tokenizer)})")
한국어에 더 특화된 GPT가 필요하기 때문에 개인정보보호에 진심이라 더 믿을 수 있는 SKT가 만든 KoGPT2를 보도록 하자.

단어 집합 크기는 51,200개다.
# 2. 커스텀 데이터셋 클래스 정의
# 데이터프레임의 텍스트를 모델에 넣을 수 있는 형태로 변환하는 공장입니다.
class NewsSummaryDataset(Dataset):
def __init__(self, df, tokenizer, max_len=512):
self.tokenizer = tokenizer
self.data = df
self.max_len = max_len
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
row = self.data.iloc[idx]
title = row['title']
text = row['document'] # 뉴스 본문
summary = row['summary'] # 정답 요약문
# [중요] 학습용 프롬프트 형식 정의
# 뉴스를 보여주고 요약을 뱉어내도록 유도하는 문자열 포맷
# 너무 길면 잘라내기 위해 본문은 앞 300자 정도만 사용 (메모리 절약 및 핵심 파악)
input_text = f"### 뉴스: {title} \n {text[:300]} \n ### 요약: {summary}" + tokenizer.eos_token
# 토크나이징 (텍스트 -> 숫자)
inputs = self.tokenizer(
input_text,
return_tensors='pt',
max_length=self.max_len,
padding='max_length',
truncation=True
)
input_ids = inputs['input_ids'][0]
attention_mask = inputs['attention_mask'][0]
# GPT 학습의 핵심: 입력(input_ids)이 곧 정답(labels)입니다. (Next Token Prediction)
return {
'input_ids': input_ids,
'attention_mask': attention_mask,
'labels': input_ids
}
이건 데이터 전처리까지 포함해서 커스텀한 dataset 클래스다.
input_text = f"### 뉴스: {title} \n {text[:300]} \n ### 요약: {summary}" + tokenizer.eos_token이 부분에서 "### 뉴스:" 뭐 이런 지시어를 붙여서 모델에게 데이터의 구조를 가르쳐준다.
기타 부분은 다른 일반적인 거랑 똑같다.
# 3. 학습용(Train) / 검증용(Validation) 데이터 분리
# 과적합 확인을 위해 10%는 떼어놓습니다.
train_df, val_df = train_test_split(economy_df, test_size=0.1, random_state=42)
print(f"학습 데이터: {len(train_df)}개 / 검증 데이터: {len(val_df)}개")
데이터를 분리한다.

# 4. 데이터셋 인스턴스 생성
train_dataset = NewsSummaryDataset(train_df, tokenizer)
val_dataset = NewsSummaryDataset(val_df, tokenizer)
# --- 👀 잘 만들어졌는지 1개만 까서 확인해보자 ---
print("\n--- 🔍 데이터셋 샘플 확인 (디코딩 결과) ---")
sample = train_dataset[0]
print(tokenizer.decode(sample['input_ids'], skip_special_tokens=False))
print("\n✅ 데이터셋 준비가 완료되었습니다.")
데이터를 아까 커스텀한 데이터셋 클래스에 넣고 잘 됐나 보자.

잘 됐다!
이제 모델을 가져올 거다.
from transformers import GPT2LMHeadModel, TrainingArguments, Trainer, DataCollatorForLanguageModeling
# 1. 모델 로드 (Pre-trained Model)
# 토크나이저와 짝이 맞는 SKT KoGPT2 모델을 불러옵니다.
print("⏳ 모델을 다운로드하고 로드합니다...")
model = GPT2LMHeadModel.from_pretrained("skt/kogpt2-base-v2")
model.to("cuda") # GPU로 이동 (필수!)
구조는 이렇게 생겼다.

wte는 Word Token Embedding의 줄임말로, 토큰화된 거를 가져와서 임베딩 벡터로 바꾸는 걸 의미한다. 단어 사전 크기가 51,200이고, 임베딩 벡터의 차원은 768이다.
wpe는 Word Position Embedding의 줄임말로, 단어의 순서를 최대 1,024개까지 뽑는다.
그 아래를 보면 총 12개의 블록으로 구성되어 있는데 각 블록을 뜯어보면 크게 2개로 나뉘는 걸 알 수 있다. (Layer Norm은 물론 각각의 앞에 붙는다.) 첫 번째는 GPT2Attention으로 문장 안에서 단어들끼리 관계를 파악한다. 두 번째는 GPT2MLP로 어텐션이 파악한 정보를 바탕으로 데이터를 더 고차원적으로 처리한다.
이걸 다 하면 마지막에 다시 Layer Norm하고 최종적으로 lm_head 레이어를 통해서 768 차원의 임베딩 벡터를 51,200개의 단어 후보로 되돌린다.
(attn): GPT2Attention(
(c_attn): Conv1D(nf=2304, nx=768)
(c_proj): Conv1D(nf=768, nx=768)
(attn_dropout): Dropout(p=0.1, inplace=False)
(resid_dropout): Dropout(p=0.1, inplace=False)
)
요것도 자세히 보면 좋을 것 같은데,
- c_attn: 입력으로 임베딩 벡터의 차원에 해당하는 768을 받고 이걸 Q, K, V로 만들어야 하므로 3배를 해서 2,304로 확장한다.
- c_proj: 어텐션을 할 때 여러 개로 쪼갠 헤드의 정보를 하나로 합친다.
(mlp): GPT2MLP(
(c_fc): Conv1D(nf=3072, nx=768)
(c_proj): Conv1D(nf=768, nx=3072)
(act): NewGELUActivation()
(dropout): Dropout(p=0.1, inplace=False)
)
- c_fc: 이번에는 4배로 뻥튀기해서 모델이 더 복잡한 지식을 저장할 수 있도록 한다.
- act: 활성화 함수
- c_proj: 다시 768 차원으로 줄인다.
# 2. 학습 설정 (TrainingArguments) - 여기가 제일 중요!
# 구글 드라이브 경로에 저장해야 날아가지 않습니다.
output_dir = '/content/drive/MyDrive/News_Summary_Project/output'
training_args = TrainingArguments(
output_dir=output_dir, # 저장될 경로
num_train_epochs=3, # 학습 반복 횟수 (3번이면 충분)
per_device_train_batch_size=8, # 한 번에 학습할 데이터 양 (GPU 메모리에 맞춰 조절)
per_device_eval_batch_size=8, # 검증할 때 데이터 양
logging_dir='./logs', # 로그 저장 경로
logging_steps=100, # 100 step마다 로그 출력 (Loss 확인용)
save_strategy="epoch", # 1 epoch 끝날 때마다 임시 저장
eval_strategy="epoch", # 1 epoch 끝날 때마다 검증
learning_rate=5e-5, # 학습률 (너무 크면 못 배우고, 너무 작으면 느림)
weight_decay=0.01, # 과적합 방지용 규제
warmup_steps=200, # 초반에 천천히 학습 시작 (안정성)
save_total_limit=2, # 용량 아끼기 위해 최근 2개 모델만 남김
)
학습 설정을 적당히 하고,
# 3. 트레이너(Trainer) 정의
# 선생님 역할을 하는 객체입니다. 모델, 설정, 데이터를 다 넘겨줍니다.
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=val_dataset,
# 데이터가 입력될 때 배치를 예쁘게 묶어주는 역할 (기본값 사용)
data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False),
)
트레이너를 만든다. 이걸 하면 모델 학습 과정이 자동화돼서 아주 편해진다. 얘는 데이터 로드, 순전파, 손실 계산, 역전파, 업데이트, 평가, 저장 등을 쉽게 할 수 있도록 도와준다.
Data Collator는 데이터를 배치로 묶어줄 뿐만 아니라 패딩 처리, 텐서 변환 등도 도와준다. 이건 gpt니까 mlm은 꺼준다.
# 4. 학습 시작! (Start Training)
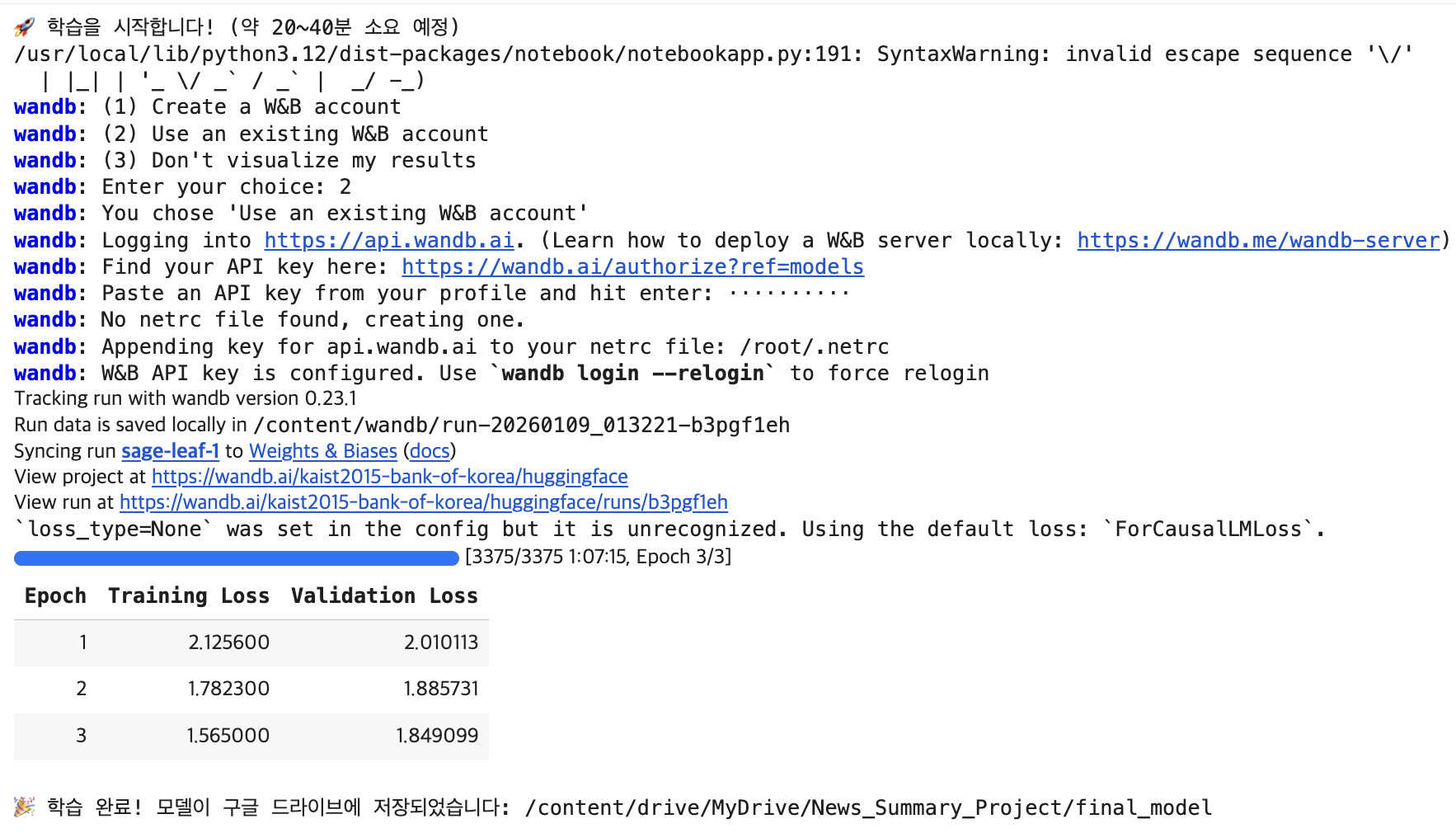
print("🚀 학습을 시작합니다! (약 20~40분 소요 예정)")
trainer.train()
# 5. 최종 모델 저장 (가장 중요)
# 학습이 끝나면 최종 결과물을 드라이브에 'final_model'이라는 이름으로 저장합니다.
final_path = '/content/drive/MyDrive/News_Summary_Project/final_model'
model.save_pretrained(final_path)
tokenizer.save_pretrained(final_path)
print(f"\n🎉 학습 완료! 모델이 구글 드라이브에 저장되었습니다: {final_path}")
학습을 시작한다. T4 GPU로 했는데 1시간 정도 걸렸다. 담부턴 L4를 도전해야겠다.
이제 모델을 불러오고 테스트를 해보자!
from transformers import PreTrainedTokenizerFast, GPT2LMHeadModel
import torch
# 1. 저장된 모델 불러오기 (구글 드라이브)
save_path = '/content/drive/MyDrive/News_Summary_Project/final_model'
print(f"📂 저장된 모델을 불러옵니다: {save_path}")
try:
model = GPT2LMHeadModel.from_pretrained(save_path)
tokenizer = PreTrainedTokenizerFast.from_pretrained(save_path,
bos_token='</s>',
eos_token='</s>',
unk_token='<unk>',
pad_token='<pad>',
mask_token='<mask>')
print("✅ 모델 로드 성공!")
except Exception as e:
print(f"❌ 모델 로드 실패: {e}")
# 혹시 로드 실패하면 코랩 세션에 있는 걸 바로 쓰도록 처리
print("메모리에 있는 모델을 그대로 사용합니다.")
# GPU로 이동
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# 2. 요약 생성 함수 정의
def summarize_news(news_text):
# 학습 때와 똑같은 형식으로 입력을 만들어줍니다.
input_text = f"### 뉴스: {news_text} \n ### 요약:"
# 텍스트 -> 숫자 (토큰화)
input_ids = tokenizer.encode(input_text, return_tensors='pt').to(device)
# 모델에게 뒷내용 생성 요청
with torch.no_grad():
output_ids = model.generate(
input_ids,
max_length=512, # 최대 길이
num_beams=3, # 3개의 길을 찾아보고 가장 좋은 것 선택 (Beam Search)
early_stopping=True, # <eos> 나오면 즉시 종료
no_repeat_ngram_size=3, # 같은 말 3번 반복 금지
repetition_penalty=1.2, # 반복 억제 페널티
eos_token_id=tokenizer.eos_token_id # 문장 종료 토큰 지정
)
# 숫자 -> 텍스트 (디코딩)
generated_text = tokenizer.decode(output_ids[0], skip_special_tokens=True)
# 프롬프트 부분 제거하고 요약만 추출
summary = generated_text.split("### 요약:")[-1].strip()
return summary
테스트에서 사용할 함수를 만든다. 이건 입력 데이터를 모델이 추론하기 좋은 형식으로 바꾸고 추론까지 하는 함수다.
이제 테스트를 하자!
from transformers import PreTrainedTokenizerFast, GPT2LMHeadModel
import torch
# GPU 설정
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 1. 토크나이저 로드 (공통 사용)
# 저장된 경로에서 불러옵니다.
save_path = '/content/drive/MyDrive/News_Summary_Project/final_model'
tokenizer = PreTrainedTokenizerFast.from_pretrained(save_path,
bos_token='</s>', eos_token='</s>',
unk_token='<unk>', pad_token='<pad>', mask_token='<mask噠>')
# 2. 두 모델 불러오기 (비교용)
print("⏳ 모델 로딩 중... (메모리 확보를 위해 잠시 시간이 걸립니다)")
# (1) 순정 모델 (Base Model) - 학습 전
original_model = GPT2LMHeadModel.from_pretrained("skt/kogpt2-base-v2").to(device)
# (2) 튜닝된 모델 (Fine-tuned Model) - 학습 후
finetuned_model = GPT2LMHeadModel.from_pretrained(save_path).to(device)
print("✅ 두 모델 로드 완료! 대결을 시작합니다.\n")
# 3. 비교 함수 정의
def compare_models(news_text):
# 학습 때 썼던 프롬프트 형식 그대로 적용
input_text = f"### 뉴스: {news_text} \n ### 요약:"
tokenized_text = tokenizer(input_text, return_tensors="pt").to(device)
# 생성 옵션 설정 (동일한 조건)
gen_params = {
"max_length": 512,
"num_beams": 3,
"early_stopping": True,
"no_repeat_ngram_size": 3,
"eos_token_id": tokenizer.eos_token_id
}
print(f"📰 [입력 뉴스 본문] (일부 생략)\n{news_text[:150]}...\n")
print("-" * 50)
# --- A. 학습 전 (Original) ---
with torch.no_grad():
out_origin = original_model.generate(tokenized_text['input_ids'], **gen_params)
decoded_origin = tokenizer.decode(out_origin[0], skip_special_tokens=True)
# 프롬프트 제거하고 순수 생성물만 추출
res_origin = decoded_origin.split("### 요약:")[-1].strip()
print(f"❌ [Before] 학습 전 모델의 답변:\n{res_origin}")
print("-" * 50)
# --- B. 학습 후 (Fine-tuned) ---
with torch.no_grad():
out_finetuned = finetuned_model.generate(tokenized_text['input_ids'], **gen_params)
decoded_finetuned = tokenizer.decode(out_finetuned[0], skip_special_tokens=True)
res_finetuned = decoded_finetuned.split("### 요약:")[-1].strip()
print(f"⭕ [After] 파인튜닝 모델의 답변:\n{res_finetuned}")
print("=" * 50)
# 4. 실제 테스트 데이터 입력
test_news_1 = """
미국 연방준비제도(Fed)가 기준금리를 동결했다. 제롬 파월 의장은 물가 상승률이 목표치인 2%로 내려가고 있다는 확신이 들 때까지 금리 인하는 없을 것이라고 못 박았다.
시장에서는 연내 금리 인하 기대감이 있었으나, 파월 의장의 매파적 발언으로 인해 뉴욕 증시는 일제히 하락 마감했다.
특히 기술주 중심의 나스닥 지수는 1.5% 넘게 떨어지며 큰 낙폭을 보였다.
"""
compare_models(test_news_1)
# 사용자 입력 테스트
user_input = input("\n직접 테스트할 뉴스를 입력하세요 (엔터): ")
if user_input:
compare_models(user_input)
요렇게 대충 넣어주면,

캬! 잘 된 걸 알 수 있다.
fine-tuning하기 전의 gpt가 왜 이 모양이냐면얘는 그냥 인터넷에 있는 방대한 텍스트를 학습한 것에 불과하기 때문이다. 후반부에 신촌 얘기가 반복되는데 이것도 gpt 모델 특유의 반복 지옥에 빠진 것이다.
'이분 전산학부 졸업한 거 아닌가요? > AI, ML, Data' 카테고리의 다른 글
| 어텐션 조지기! (Bahdanau & Luong Attention) (0) | 2026.02.06 |
|---|---|
| 아주 간단한 차이: 딥러닝 vs 머신러닝 (0) | 2026.02.01 |
| 구글의 BERT (BUTT 아님) (0) | 2026.01.08 |
| 로라로라로라로라(LoRA) - 전이학습 효율 개지림 (0) | 2026.01.07 |
| Seq2Seq에 Attention을 추가해 보자! (1) | 2026.01.02 |
한국은행 들어갈 때까지만 합니다



