

오늘은 진짜 강화학습을 배우고 DQN 실습까지 해볼 것이다!
를 진짜 하려고 했는데 강화학습의 다양한 알고리즘을 살펴보는 글이 되었다,,

강화학습(RL: Reinforcement Learning)은 머신러닝의 한 분야다. 인간이 "보상(reward) 함수"를 설정하면, 이걸 최대화하기 위해 컴퓨터(agent)가 어떤 상태(state)에서 어떤 행동(action)을 해야 하는지 알아서 학습한다.

아기가 걸음마를 배우듯이 시도하고 실패하고,, 그것의 반복이다.
- 에이전트가 현재 상태를 확인한다.
- 에이전트가 특정 기준(정책)에 따라 행동을 수행한다.
- 환경을 업데이트하고 그에 따른 보상을 받는다.
- 에이전트는 받은 보상을 바탕으로, 더 많은 보상을 얻을 수 있도록 정책을 수정한다.
강화학습에 쓰이는 알고리즘을 여러 가지로 분류할 수 있다.
모델이 있는/없는 상태로 배우냐?
- Model-Free RL: 환경이 어떻게 돌아가는지 모르는 채 맨땅에 헤딩으로 배운다. 환경이 엄청 복잡해서 직접 설정하기 어려울 때 사용하면 좋지만, 이것저것 다 해봐야 하기 때문에 학습 속도가 느리고 데이터도 많이 필요하다.
- DQN, PPO, SAC 등 대부분의 범용 알고리즘이 여기에 해당한다.
- Model-Based RL: 에이전트가 환경이 어떻게 돌아가는지 알고 있는 상태에서 학습한다. 실제로 움직이기 전에 머릿속으로 시뮬레이션을 돌려볼 수 있어서 효율적이다. 물론 내부 모델이 실제 환경과 다르면 성능이 박살 난다.
- AlphaZero, World Models, Dreamer 등의 알고리즘이 여기에 해당한다.
각 알고리즘을 가볍게 살펴보자.
DQN (Deep Q-Network)

DQN은 Q-Learning에 딥러닝을 결합해서 게임 화면 같은 고차원 입력을 처리할 수 있게 만든 알고리즘이다. Value-based 강화학습의 큰행님이라고 할 수 있다.
(참고로 Q-Learning은 특정 상태에서 특정 행동을 취했을 때 기대되는 미래 보상의 총합인 Q-Value(Quality Value)를 최대화하도록 학습하는 것)
왜 Q-Learning에 딥러닝을 도입했냐? 그냥 Q-Learning만 하면 모든 상태와 행동 조합에 대한 Q값을 표에 기록해야 하는데, 조금이라도 복잡해지면 이걸 다 적어놓는 것이 불가능하기 때문에 각 조합에 대한 Q값을 딥러닝을 통해서 예측하는 것이 훨씬 낫다.
PPO (Proximal Policy Optimization)
PPO는 정책 기반이다. DQN이랑 가장 큰 차이는, DQN은 가치 기반이라서 점수표를 기반으로 점수가 가장 높은 행동을 선택하는 것이지만, 정책 기반은 점수표를 거치지 않고, 특정 상태에서 어떤 행동을 해야 하는지의 확률 자체를 학습한다. 그러니까 신경망의 출력이 "이 행동을 할 확률은 70%임 ㅇㅇ" 이라고 직접 나오는 것이다.
제일 큰 차이가 뭐냐? 가치 기반은 Q값이 가장 높은 것을 선택(결정론적 방식)하는 반면, 정책 기반은 확률적이기 때문에 별도의 장치가 없어도 자연스럽게 exploration이 가능하다는 것이다. 또한 연속적인 공간에서도 작동할 수 있다. (연속적이면 당연히 점수표를 만들 수 없음)
암튼 PPO는 이렇게 정책 기반인데 Clipped Objective가 있어서 정책이 너무 휙휙 바뀌지 않게끔 안전장치를 마련했다.
SAC (Soft Actor-Critic)

SAC는 보상만 최대화하는 게 아니라 엔트로피도 함께 최대화한다. 엔트로피를 높인다는 것은? 다양한 행동을 하는 것을 의미한다. 덕분에 에이전트가 특정 행동에만 매몰되지 않고 Exploration을 지속해서 Local Minima에 빠지는 것을 막는다.
최근에 가장 뛰어난 성능을 보이는 알고리즘이다! 다만 하이퍼파라미터 설정이 약간 까다롭다.
이름이 왜 Actor-Critic이냐, ㄹㅇ로 배우와 비평가의 관계기 때문이다. Actor(배우)는 현재 상태에서 어떤 행동을 할지 결정하는 정책 역할을 한다. 에이전트가 실제 움직이는 부분이다. Critic(비평가)은 Actor의 행동을 보고 그 행동이 얼마나 괜찮았나 가치를 평가한다. 에이전트를 이원화한다는 뜻이다. 덕분에 학습의 변동성이 줄어든다.
지금까지 설명한 Model-Free RL에 해당하는 위의 세 가지 알고리즘을 정리하면 다음과 같다.
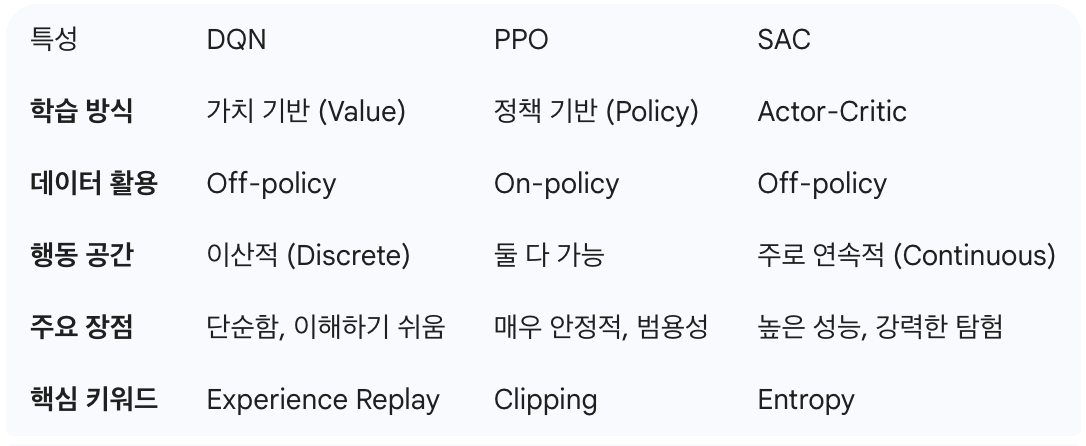
참고로 On-Policy와 Off-Policy의 차이는 뭐냐면,
On-Policy는 자신이 지금 가지고 있는 최신 정책으로 움직여서 얻은 데이터로만 학습하는 방식이다. 내가 지금 생각하는 대로 움직이고 그 경험에서 바로 배우는 것이다. 에이전트가 직접 경험했기 때문에 정확하고 학습이 안정적이지만, 과거의 나와 지금의 나는 정책이 다르기 때문에 한 번 사용한 데이터는 버려야 한다. 그래서 데이터 효율성이 낮다.
Off-Policy는 과거의 자신 혹은 다른 에이전트가 생성한 데이터를 가져와서 현재의 정책을 학습하는 방식이다. Experience Replay Buffer라는 저장소에 데이터를 쌓아두고 필요할 때마다 꺼내쓴다. 과거 데이터를 반복해서 쓸 수 있기 때문에 데이터 효율성이 높지만, 과거는 과거기 때문에 학습이 불안정해질 수 있다. (보정하는 방법도 있지만 수식이 복잡)
이제는 Model-Based RL에 해당하는 세 친구를 보자.
AlphaZero

이름에서 알 수 있듯 한국인들은 치가 떨리는 대세돌 님을 개바른 알파고,,를 훨씬 뛰어넘는 친구다. 알파고와의 차이를 중심으로 설명하자면,
- 알파고는 처음에 인간의 기보 약 16만 개를 먼저 학습한 다음에 이걸 바탕으로 스스로 대국하면서 실력을 키웠다. 하지만 알파제로는 인간의 기보를 전혀 사용하지 않고, 게임의 기본 규칙만 안 채로 셀프 플레이를 통해 데이터를 스스로 생성했다.
- 알파고는 바둑만, 알파제로는 규칙이 있는 게임이라면 뭐든 가능하다.
- 알파제로는 신경망도 깔끔하게 다듬어서 연산 효율이 높다. (알파제로는 TPU 4개만 써도 알파고를 이긴다 ㄷㄷ)
World Models

에이전트가 복잡한 외부 환경의 물리 법칙으로 가상 세계를 구축하는 방식이다. 단계는 3개로 나뉜다.
- 1단계(Vision Model - 요약): 외부 세계의 복잡한 이미지 데이터를 VAE를 사용해서 latent space로 압축한다.
- 2단계(Memory Model - 예측): 현재의 잠재 상태와 에이전트의 행동을 바탕으로 다음 순간에 어떤 일이 벌어질지 예측한다.
- 3단계(Controller - 연습): 실제 환경에서 학습하지 않고 자신이 만든 가상의 꿈(?)속에서 여러 번 반복 학습한다. 이렇게 배운 정책을 실제 환경에 적용한다.
Dreamer
이건 World Models를 더 발전시킨 알고리즘이다. 둘 다 에이전트가 환경의 내부 모델을 학습한 다음에 상상을 통해 정책을 결정하는 건 맞지만, 미래 상태를 예측하는 방식이 서로 다르다.
World Models는 다음 상태를 예측할 때 오직 확률 분포에서 샘플링된 값에만 의존한다. 그래서 이 과정에서 발생하는 작은 오차가 RNN의 다음 입력으로 들어가면서 시간이 지날수록 오차가 커지는 문제가 발생한다.
반면에 Dreamer는 정보를 결정론적 상태와 확률적 상태로 엄격하게 분리해서 이 문제를 해결했다. 이걸 RSSM(Recurrent State Space Model)이라고 한다. 결정론적 상태는 과거의 모든 정보를 압축해서 전달하는 RNN의 은닉 상태다. 노이즈의 영향을 받지 않고 정보를 안정적으로 유지하는 단단한 기억의 역할을 한다. 확률적 상태는 확률적 분포에서 샘플링되어 매 순간 발생하는 구체적이고 불확실한 정보를 담는다.
자! 이제 이렇게 살펴봤고 다음에는 진짜 DQN을 실습해 볼 것이다!
'이분 전산학부 졸업한 거 아닌가요? > AI, ML, Data' 카테고리의 다른 글
| 어텐션 조지기! (Bahdanau & Luong Attention) (0) | 2026.02.06 |
|---|---|
| 아주 간단한 차이: 딥러닝 vs 머신러닝 (0) | 2026.02.01 |
| GPT-2를 적당히 fine-tuning해서 경제 뉴스 요약하고 주식 투자로 초대형부자가 되기 대작전! (1) | 2026.01.09 |
| 구글의 BERT (BUTT 아님) (0) | 2026.01.08 |
| 로라로라로라로라(LoRA) - 전이학습 효율 개지림 (0) | 2026.01.07 |
한국은행 들어갈 때까지만 합니다



