

https://www.kaggle.com/code/satyaprakashshukl/mushroom-classification-analysis/notebook
🌴Mushroom🎉Classification📈Analysis
Explore and run machine learning code with Kaggle Notebooks | Using data from multiple data sources
www.kaggle.com
cols_to_drop_train = missing_train[missing_train > 95].index
cols_to_drop_test = missing_test[missing_test > 95].index
df_train = df_train.drop(columns=cols_to_drop_train)
df_test = df_test.drop(columns=cols_to_drop_test)
gc.collect()
다시 결측치가 높은 column들을 떨구고, 본격적으로 impute를 해보자!

label encoding이랑 one-hot encoding은 쉬우니까 넘어가고,
아래 두 개만 더 자세히 보면,
one-hot encoding보다는 추가되는 column의 개수가 적고, label encoding처럼 의미 없는 순서를 나타내게 된다는 단점이 있을 수 있다.
target encoding은,, 설명보다 예시를 보는 게 쉬우니 예시를 보자.
여기서 색상은 독립 변수, 가격은 종속 변수인데, 색상의 종류가 엄청 많다고 해보자! 그러면 색상을 다음과 같이 바꿀 수 있다.
물론 각 범주 별로 수가 적으면 과적합이 일어난다.
from sklearn.impute import KNNImputer
import pandas as pd
def knn_impute(df, n_neighbors=5):
df_encoded = df.copy()
for col in df_encoded.select_dtypes(include='object').columns:
df_encoded[col] = df_encoded[col].astype('category').cat.codes
knn_imputer = KNNImputer(n_neighbors=n_neighbors)
df_imputed = pd.DataFrame(knn_imputer.fit_transform(df_encoded), columns=df_encoded.columns)
for col in df.select_dtypes(include='object').columns:
df_imputed[col] = df_imputed[col].round().astype(int).map(
dict(enumerate(df[col].astype('category').cat.categories)))
return df_imputed
df_train_imputed = knn_impute(df_train, n_neighbors=5)
df_test_imputed = knn_impute(df_test, n_neighbors=5)
결측치가 그리 높지 않은 column들에 대해서는 Impute를 해주면 된다.
KNN(K-Nearest Neighbors) 알고리즘은 각 데이터 포인트에서 가장 가까운 K개 이웃을 찾고 여기에 기반해 값을 예측하는 방법이다.
범주형 데이터를 숫자로 바꾸고,

KNNImputer 객체를 만든 후에,
결측값을 KNN으로 대체하고 이를 df_imputed에 저장한다.
for col in df.select_dtypes(include='object').columns:
df_imputed[col] = df_imputed[col].round().astype(int).map(
dict(enumerate(df[col].astype('category').cat.categories)))
이거를 좀 볼 필요가 있는데, 우선 기존 df에서 범주형 변수에 해당하는 columns를 선택하고,
df_imputed에서 해당 columns들의 값을 일단 반올림하고 int형을로 바꿔준다.
기존 df[col]의 값들을 확실히 범주형으로 해두고, 카테고리 값들을 가져온다. 여기에 enumerate를 사용했으므로 숫자의 key와 값의 value들이 존재하는데 이를 map을 사용함으로써 KNN을 하기 위해 숫자로 변형됐던 값들의 원래의 범주형 변수로 바뀐다.
그리하여 최종적으로 df_train_imputed와 df_test_impute가 나온다.
결측값을 처리해줬으니,, 이제 완성된 범주형 데이터를 숫자로 변환해야 한다.
cat_cols_train = df_train_imputed.select_dtypes(include=['object']).columns
cat_cols_train = cat_cols_train[cat_cols_train != 'class']
ordinal_encoder = OrdinalEncoder(handle_unknown='use_encoded_value', unknown_value=-1)
df_train_imputed[cat_cols_train] = ordinal_encoder.fit_transform(df_train_imputed[cat_cols_train].astype(str))
df_test_imputed[cat_cols_train] = ordinal_encoder.transform(df_test_imputed[cat_cols_train].astype(str))
Ordinal Encoder 객체를 생성한다. 왜 굳이 순서가 중요한 이 친구를 선택한지는 모르겠으나,, 일단 따라가자..
handle_unknown='use_encoded_value' 이것은 데이터셋에 없는 새로운 값이 등장할 경우 unknown_value 옵션에 설정된 값(-1)을 사용하는 것을 뜻한다. 이걸 안 해주면 test 데이터에 새로운 값이 있을 경우 오류가 발생한다.
astype(str)을 통해 기존 데이터를 명확하게 문자열 타입으로 바꾸고 fit_transform을 사용해 숫자형으로 바꾼다.
잘 바뀐 것을 알 수 있다.
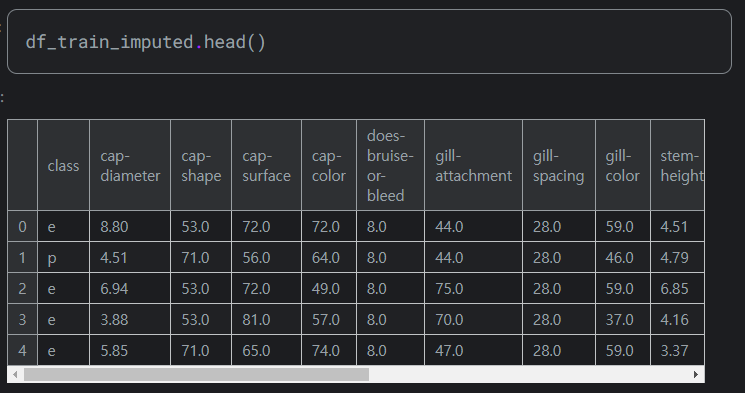
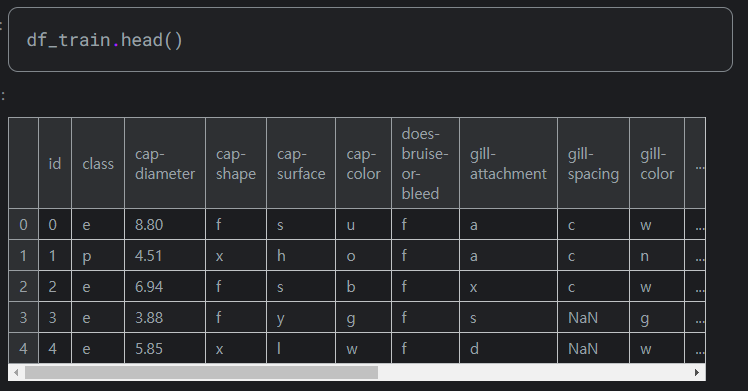
아래는 기존 데이터
마지막으로 LabelEncoder를 통해 종속 변수를 인코딩 해준다.

여기서 꿀팁은 LabelEncoder는 범주형 "타겟" 변수를, OrdinalEncoder는 범주형 "입력" 변수를 대상으로 한다.
따라서 전자는 보통 1차원이기 때문에 입력으로 1차원 배열만 받고, 후자는 여러 개를 한 번에 받는다.
'분명 전산학부 졸업 했는데 코딩 개못하는 조준호 > AI, ML, DL' 카테고리의 다른 글
한국은행 들어갈 때까지만 합니다
조만간 티비에서 봅시다
-
 Kaggle Competition - Binary Prediction of Poisonous Mushrooms (6) 최종 제출2024.09.08
Kaggle Competition - Binary Prediction of Poisonous Mushrooms (6) 최종 제출2024.09.08 -
 Kaggle Competition - Binary Prediction of Poisonous Mushrooms (5) 모델 학습 및 생성2024.09.06
Kaggle Competition - Binary Prediction of Poisonous Mushrooms (5) 모델 학습 및 생성2024.09.06 -
 Kaggle Competition - Binary Prediction of Poisonous Mushrooms (3) EDA 시각화2024.09.02
Kaggle Competition - Binary Prediction of Poisonous Mushrooms (3) EDA 시각화2024.09.02 -
 Kaggle Competition - Binary Prediction of Poisonous Mushrooms (2) EDA correlation matrix2024.09.02
Kaggle Competition - Binary Prediction of Poisonous Mushrooms (2) EDA correlation matrix2024.09.02