

이전 글과 아주 비슷하다.
https://kaist2015.tistory.com/63
네이버 오픈 API 사용해서 "검색" 데이터 긁어오기
https://developers.naver.com/main/ NAVER Developers네이버 오픈 API들을 활용해 개발자들이 다양한 애플리케이션을 개발할 수 있도록 API 가이드와 SDK를 제공합니다. 제공중인 오픈 API에는 네이버 로그인, 검
kaist2015.tistory.com
이번에는 여기서 긁어오자.
공공데이터 포털
국가에서 보유하고 있는 다양한 데이터를『공공데이터의 제공 및 이용 활성화에 관한 법률(제11956호)』에 따라 개방하여 국민들이 보다 쉽고 용이하게 공유•활용할 수 있도록 공공데이터(Datase
www.data.go.kr

여기서 "소상공인"으로 검색해 보자.

뭐 이것저것 많은데 우리는 여기서 맨 위에 있는 친구를 선택할 거다.
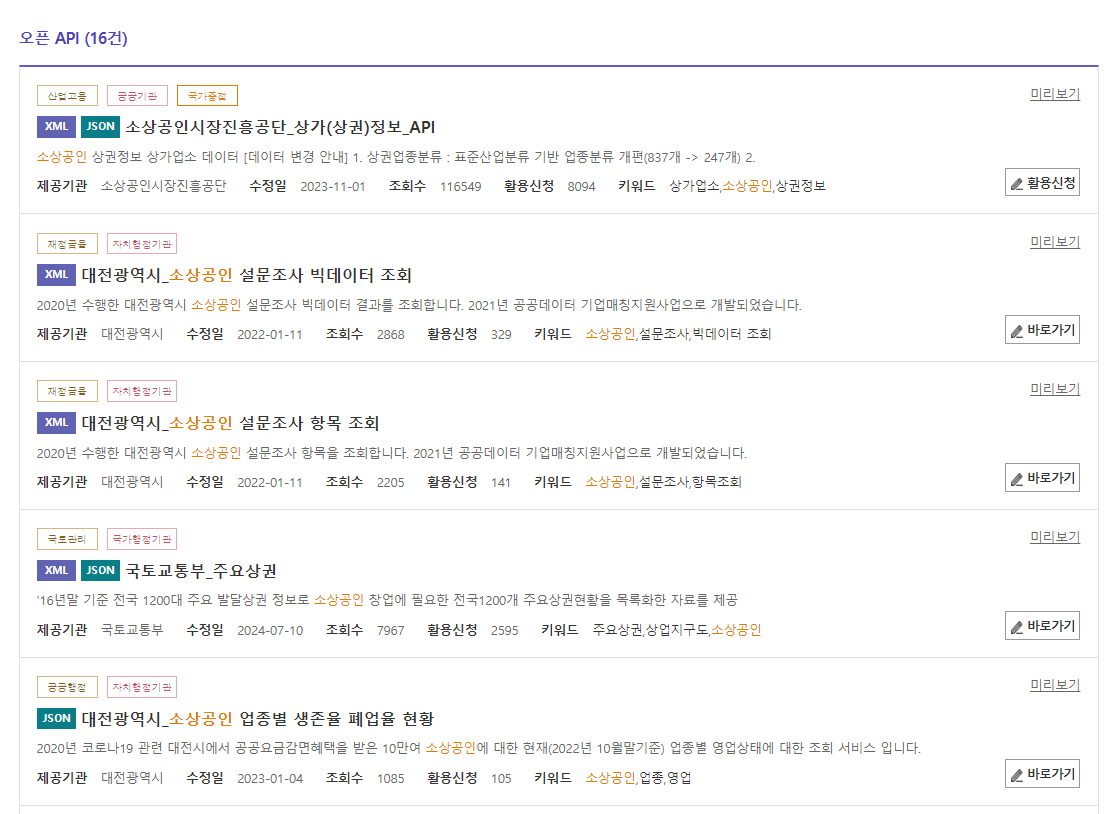
이렇게 상세히 나온다.

오른쪽 위에 있는 활용신청을 누르자!
아래로 더 내려보면 "API 목록"이 엄청 많이 있는데 여기서 "업종별 상가업소 조회"를 볼 것이다.

열어보면 이것저것 많이 나와있는데, 여기서 각 parameter들을 입력해 주면 미리 보기로 확인할 수도 있다. 귀찮으니 생략~

코드로 풀기 위해서는 참고문서에 있는 이 압축 파일을 열어서 봐야 한다.

여기에 이것저것 들어있는데
여기서 두 번째에 있는 한글 파일을 열어보면 아주 자세하게 뭘 해야 하는지 알 수 있다.

아주 친절하다! 요청을 보낼 때 이 친구들을 params에 넣어줘야 한다.

응답 메시지로 뭐가 나오는지도 알려줌.
더 아래로 내려가면,

이렇게 URI가 나온다. 여기로 요청을 보내면 된다.
잠깐 곁다리로 URI, URL, URN에 대해 설명을 하자면,


URI는 URL과 URN을 포함한다.
그리고 세 번째 엑셀 파일을 열어보면,

아주 상세하게 분류 코드가 들어있으니 본인이 보고 싶은 분류코들 넣어주면 된다.
나는 치킨집을 가져올 거다.
암튼! 이제 직접 코드를 만들어서 데이터를 빼오자.
%%time
servicekey = os.getenv('servicekey')
divId = "indsSclsCd"
key = "I21006"
numOfRows = 1000
url = 'http://apis.data.go.kr/B553077/api/open/sdsc2/storeListInUpjong'
page = 1
payload = {
'servicekey': servicekey,
'divId': divId,
'key': key,
'numOfRows': numOfRows,
'pageNo': page,
'type': 'json',
}
response = requests.get(url, params=payload)
맨 위에 %%time은 jupyter에서만 사용하는 건데 전체 실행시간을 알려준다.
그 아래로는 requests 라이브러리를 통해 url과 params들을 넣어주면 response 객체가 반환된다.
이 객체는 해당 url에 들어가서 정보를 빼오는 역할을 한다는 것을 기억하겠지!
그나저나 params에는 어떤 것을 넣어야 할까?
그것은 그때그때 다르다.
요청 메시지 명세를 보면 된다.

여기 있는 거 그냥 순서대로 넣어준 겁니다^^
그런데 servicekey는 os.getenv('servicekey')를 이용해서 넣어줬는데 이건 뭘까?
이건 servicekey는 비밀에 해당하기 때문에 이걸 그대로 코드에 넣고 github에 올리면 개인정보가 줘 털리는 불상사가 발생하기 때문에 묘책(?)을 사용한 것이다.
우선 pip install python-dotenv를 해서 해당 가상환경에 이 라이브러리를 설치하고,(jupyter면 앞에 느낌표(!) 붙이는 거 알지~~)
.env 파일을 (루트 디렉토리에) 만들어서 거기에 나만의 key를 쓰면 된다.

나는 이렇게 만들었다.
.env 파일을 자세히 보면 이렇게 나오는데,

이렇게 들어있다.
그리고 이 .env는 github에 올리지 않기 위해서 .gitignore를 (역시 루트 디렉터리에) 만들고 거기에 ".env"라고 쓰면 된다.

그냥 이렇게 쓰면 됨 ^^
아모튼 이걸 쓰기 위해서는 정리해 보자면
pip install python-dotenv #(jupyter는 앞에 느낌표 붙이기)
import os
from dotenv import load_dotenv
load_dotenv()
이렇게 하면 된다.
우리의 비밀번호를 얻기 위해서는
servicekey = os.getenv('servicekey')
요렇게 쓰면 된다. getenv() 안에 들어있는 변수 이름이랑 .env 안에 들어있는 변수 이름을 맞춰줘야 한다.
자자, 그러면 앞에 이거는 완료!
%%time
servicekey = os.getenv('servicekey')
divId = "indsSclsCd"
key = "I21006"
numOfRows = 1000
url = 'http://apis.data.go.kr/B553077/api/open/sdsc2/storeListInUpjong'
page = 1
payload = {
'servicekey': servicekey,
'divId': divId,
'key': key,
'numOfRows': numOfRows,
'pageNo': page,
'type': 'json',
}
response = requests.get(url, params=payload)
그리고 데이터를 빼올 때 넘 오래 걸리니까 되는대로 계속해서 진행 상황을 알려주는 이걸 만들고 싶으니까

분모에 해당하는 40을 얻기 위해 전체 total_pages를 얻어야 한다. 그러기 위한 코드는 다음과 같다.
if response.status_code == 200:
try:
data = response.json()
total_count = data.get('body', {}).get('totalCount', 0)
total_pages = math.ceil(total_count / numOfRows)
except json.JSONDecodeError as e:
print(f"JSONDecodeError: {e.msg}")
print("Raw response text:")
print(response.text)
total_count = 0
total_pages = 1
else:
print(f"Failed to retrieve data. Status code: {response.status_code}")
total_count = 0
total_pages = 1
뭔가 문제가 발생하면 다 기본값 & 에러처리 해버리고 잘 가져오면 response의 값을 json으로 바꾸고 total_count를 가져온 다음에 그 값을 numOfRows로 나눈 값을 올림 처리해서 총 몇 페이지나 가져와야 하나에 대한 값을 얻는다.
이걸 total_pages에 저장하면 됨!
combined_df = pd.DataFrame()
while page <= total_pages:
payload['pageNo'] = page
response = requests.get(url, params=payload)
if response.status_code == 200:
try:
data = response.json()
if 'body' in data and 'items' in data['body'] and data['body']['items']:
df = pd.json_normalize(data['body']['items'])
combined_df = pd.concat([combined_df, df], ignore_index=True)
print(f"\rPage {page} fetched successfully ({page}/{total_pages})", end='')
page += 1
else:
print("\nNo more data found in the response")
break
except json.JSONDecodeError as e:
print(f"\nJSONDecodeError: {e.msg}")
print("Raw response text:")
print(response.text)
break
else:
print(f"\nFailed to retrieve data. Status code: {response.status_code}")
break
print(f"\nTotal records fetched: {len(combined_df)}")
display(combined_df)
다음으로 뭐가 많은데 별거 없음.
페이지가 갱신되면서 새로운 데이터를 계속 뽑아와야 하기 때문에 얘네들을 저장할 수 있는 combined_df를 만들고,
페이지 끝까지 돌기 위한 while문을 돌린다. page가 total_pages를 넘으면 끝나게끔.
지정해 준 page를 pageNo값에 넣어주고 response 객체를 만든다.
얘를 이래 저래 가져온 다음에 구해온 값에 data['body']['items']가 제대로 들어있는지 확인을 하고 있으면 가져온다. (이 코드가 없으면 비어있는 값을 무한으로 계속 가져오기 때문에 조심!)
그걸 가져오고 json_normalize()를 통해 JSON 데이터를 dataframe으로 바꿔준다.
(json()는 http 응답을 JSON 데이터로 바꾸기 위해 사용하는 함수다)
그렇게 df가 만들어졌으면 이걸 combined_df에 합쳐주고, print 함수를 통해 현재 몇 페이지를 처리하고 있는지 출력한다.
그다음에 page에 1을 더하면 됨!
이걸 끝까지 반복하면 된다.

요로코롱 나온다.
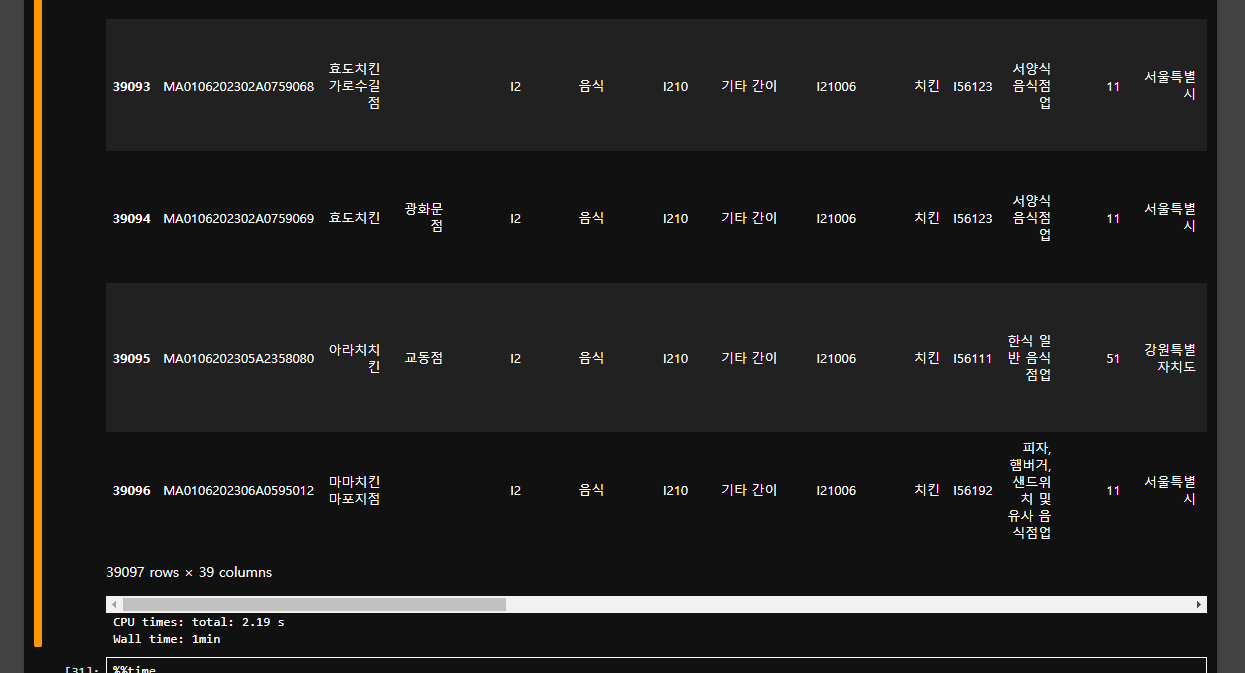
총 39097개의 치킨집이 있는 것을 알 수 있다.
그런데 정작 cpu times는 2.19초인 반면 wall time은 1분이나 되는 것을 알 수 있다.
이것은 I/O Bound로 프로그램이 주로 I/O 작업을 수행하고 있다는 것을 의미한다. 외부에서 정보를 요청하는 데 시간이 오래 걸린다는 것이다. (당연하다 정보를 가져오는 거니까)
그런 경우에는 I/O 작업을 비동기로 처리하거나 병렬 처리를 통해 대기 시간을 줄일 수 있다.
ThreadPoolExecutor를 사용해서 병렬 처리를 해보자.
대부분 비슷하고 아래 코드만 잠깐 달라진다.
%%time
# 설정
servicekey = os.getenv('servicekey')
divId = "indsSclsCd"
key = "I21006"
numOfRows = 1000
url = 'http://apis.data.go.kr/B553077/api/open/sdsc2/storeListInUpjong'
# 결합할 빈 데이터프레임 생성
combined_df = pd.DataFrame()
# 첫 번째 요청을 통해 totalCount를 가져오기
payload = {
'servicekey': servicekey,
'divId': divId,
'key': key,
'numOfRows': numOfRows,
'pageNo': 1,
'type': 'json',
}
response = requests.get(url, params=payload)
if response.status_code == 200:
try:
data = response.json()
total_count = data.get('body', {}).get('totalCount', 0)
total_pages = math.ceil(total_count / numOfRows)
except json.JSONDecodeError as e:
print(f"JSONDecodeError: {e.msg}")
print("Raw response text:")
print(response.text)
total_count = 0
total_pages = 1 # 기본적으로 1페이지로 설정하여 루프가 종료되도록 함
else:
print(f"Failed to retrieve data. Status code: {response.status_code}")
total_count = 0
total_pages = 1 # 기본적으로 1페이지로 설정하여 루프가 종료되도록 함
# 병렬 요청을 처리하는 함수
def fetch_page(page):
payload['pageNo'] = page
response = requests.get(url, params=payload)
if response.status_code == 200:
try:
data = response.json()
if 'body' in data and 'items' in data['body'] and data['body']['items']:
return pd.json_normalize(data['body']['items'])
else:
return pd.DataFrame()
except json.JSONDecodeError:
return pd.DataFrame()
else:
return pd.DataFrame()
# 데이터 수집
with ThreadPoolExecutor(max_workers=10) as executor:
future_to_page = {executor.submit(fetch_page, page): page for page in range(1, total_pages + 1)}
for future in as_completed(future_to_page):
page = future_to_page[future]
try:
df = future.result()
if not df.empty:
combined_df = pd.concat([combined_df, df], ignore_index=True)
print(f"\rPage {page} fetched successfully ({page}/{total_pages})", end='')
except Exception as exc:
print(f'\nPage {page} generated an exception: {exc}')
print(f"\nTotal records fetched: {len(combined_df)}")
display(combined_df)
우선 import를 해와야 한다.
from concurrent.futures import ThreadPoolExecutor, as_completed
요거를 하고 여기서 다른 부분은 아래 부분이니까 이것만 떼오자.
with ThreadPoolExecutor(max_workers=10) as executor:
future_to_page = {executor.submit(fetch_page, page): page for page in range(1, total_pages + 1)}
for future in as_completed(future_to_page):
page = future_to_page[future]
try:
df = future.result()
if not df.empty:
combined_df = pd.concat([combined_df, df], ignore_index=True)
print(f"\rPage {page} fetched successfully ({page}/{total_pages})", end='')
except Exception as exc:
print(f'\nPage {page} generated an exception: {exc}')
첫 줄을 통해 최대 10개의 스레드를 가진 ThreadPoolExecutor 객체를 생성하고 이를 executor라는 이름으로 사용하는 것을 알 수 있다. 굳이 with ~ as ~ 를 사용한 이유는 해당 블록이 종료될 때 만들어둔 스레드 풀을 자동으로 종료하기 위해서다.
스레드는 프로그램이 동시에 여러 작업을 수행하게 할 수 있는 실행 단위다. (대기시간이 많기 때문에 스레드를 여러 개 펼쳐놓으면 빨라진다.)

다음 줄이 중요한데,
future_to_page = {executor.submit(fetch_page, page): page for page in range(1, total_pages + 1)}
executor 객체에 submit 함수를 호출한다. (위에서 만들어준) fetch_page 함수와 page라는 parameter를 넣는다. (page는 1부터 total_pages까지 존재)
그러니까 fetch_page(1)부터 fetch_page(total_pages)까지 여러 개의 함수들이 있는데 얘네들을 비동기적으로 실행하는 것이다. 그렇게 나온 값은 Future 객체로 반환되며 이는 딕셔너리로 저장된다.
다음 줄도 중요한데 ㅋㅁㅋ,
for future in as_completed(future_to_page):
as_completed()는 Future 객체들이 완료되는 순서대로 실행된다.
그 뒤에 각각 try ~ except를 처리하는 것이다.
try:
df = future.result()
if not df.empty:
combined_df = pd.concat([combined_df, df], ignore_index=True)
print(f"\rPage {page} fetched successfully ({page}/{total_pages})", end='')
except Exception as exc:
print(f'\nPage {page} generated an exception: {exc}')
이렇게 보면 전체 코드가 이해가 될 것이다!
그나저나 이렇게 하고 로그를 확인하면,

이렇게 나오는 것을 확인할 수 있는데 이건 38번째까지만 정보를 받고 39, 40번째는 받지 않았다는 것일까?
그렇지 않다.
그냥 38번째 페이지를 불러오는데 제일 오래 걸려서 그게 가장 나중에 출력됐을 뿐이다.
그 아래 39097개 데이터 숫자를 보면 잘 불러왔음을 알 수 있다.

역시 잘 나왔는데, 시간이 엄청나게 빨라진 것을 알 수 있다!
'분명 전산학부 졸업 했는데 코딩 개못하는 조준호 > Web' 카테고리의 다른 글
| 프론트엔드 & 백엔드 포함된 초간단 서비스 만들어 보기 - (2) 백엔드의 주요 기술 스택(언어, 프레임워크, DB, 웹서버, API 방식) (1) | 2024.10.12 |
|---|---|
| 프론트엔드 & 백엔드 포함된 초간단 서비스 만들어 보기 - (1) 프론트엔드의 주요 라이브러리/프레임워크 (0) | 2024.10.04 |
| 네이버 오픈 API 사용해서 "검색" 데이터 긁어오기 (5) | 2024.07.22 |
| CSS 적용 우선순위 - 기타 중요한 사항 총정리 (1) | 2024.07.02 |
| CSS 적용 우선순위 - 선택자끼리의 비교 (1) | 2024.07.02 |
한국은행 들어갈 때까지만 합니다
조만간 티비에서 봅시다



