

https://apply.bok.or.kr/board/recruitLibraryView.do
대한민국 최고 경제전문가 집단 :: 한국은행 #1
▼ 아랫글 해당 글이 존재하지 않습니다.
apply.bok.or.kr

🔎 이분산 (heteroskedasticity)
데이터 분산이 일정하지 않은 경우
회귀 분석에서는 데이터가 독립 변수의 값에 따라 얼마나 흩어지는지를 살펴보는데, 이 흩어짐이 일정하지 않은 것
이분산 문제가 있으면 회귀 분석의 결과가 틀릴 수 있음.
🔎 통상최소자승 (OLS; Ordinary Least Squares)
독립 변수와 종속 변수 사이의 선형 관계를 추정하는 방법 👉 데이터에 가장 잘 맞는 선을 긋는 것
잔차(실제 데이터 값과 예측 값의 차이)의 제곱합을 최소화해야 함.
🙋♂️ 이분산이 존재할 때, OLS 추정량은 어떠한 특성을 갖는가?
1️⃣ 불편성(Unbiasedness)
불편성❓ 추정량의 기댓값이 모집단의 실제 값과 같음
이분산이 존재해도, 분산이 크든 작든 데이터는 결국 기댓값을 중심으로 분포되기 때문
2️⃣ 일치성(Consistency)
일치성❓ 표본 크기가 증가할수록 추정량이 실제 값으로 수렴
OLS 추정량은 일치성을 유지
따라서, 표본의 크기가 크고 독립 변수의 분포가 안정적이면 이분산이 존재하더라도 OLS 추정량은 일치성을 가짐
3️⃣ 비효율성(Inefficiency)
비효율성❓ 추정량이 최소 분산을 가지지 않는다는 것 👉 동일한 데이터로 다른 추정 방법을 사용했을 때 더 작은 분산을 가지는 추정량을 얻을 수 있음
🤔 불편성과 비효율성이 어떻게 동시에 충족돼?
불편성은 추정량이 체계적으로 과대(소)평가되지 않는다는 것 👉 여러 번 계산된 추정량의 평균이 실제 파라미터 값과 일치한다는 것
효율성은 주어진 표본에서 추정량의 분산이 최소라는 것
🔽 자세한 예시


4️⃣ 잘못된 표준 오류 추정
표준 오류❓ 추정된 통계량의 표준 편차
이분산이 존재하면 OLS 추정량의 "t-통계량 및 F-통계량이 왜곡"되고 "신뢰 구간이 부정확"해짐
👉 표준 오류가 실제보다 작게 추정되면 t-통계량이 실제보다 커져 해당 회귀 계수가 유의하다는 잘못된 결론(false positive), 반대의 경우 (false negative)
t-통계량❓ 회귀 분석에서 특정 회귀 계수가 0과 유의하게 다른지를 검정 👉 0에 가깝다면 해당 계수는 독립 변수와 종속 변수의 관계를 설명하지 않기 때문
F-통계량❓ 회귀 모형 전체의 유의성을 검정 👉 t-통계량이 특정 계수를 검정했다면 F-통계량은 모형 전체가 쓸모있는지 평가
🙋♂️ 이분산을 탐지하기 위한 검정 방법에는 무엇이 있는가?
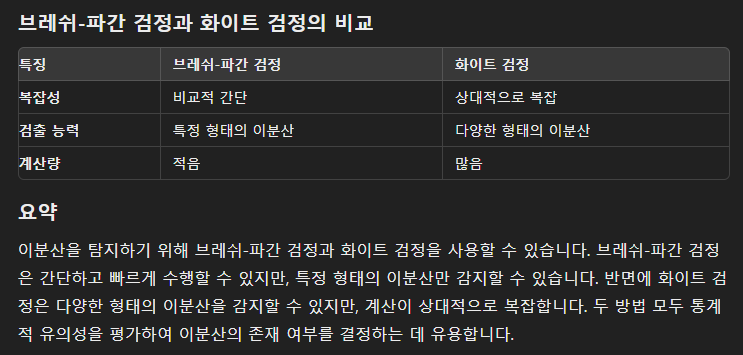
1️⃣ 브레쉬-파간 검정 (Breusch-Pagan Test)
잔차(residuals)의 제곱을 이용하여 이분산의 존재 여부를 검정하는 방법.

2️⃣ 화이트 검정 (White Test)
잔차의 제곱을 이용한다는 것은 위와 같으나 '다양한 형태'의 이분산을 검정할 수 있다는 점이 차이.
(아래 사진에서 3번, 4번 빼고 다 같음(4번도 사실상 같은 것))

'한국은행 총재 조준호 > 한국은행 필기 풀이' 카테고리의 다른 글
| 2024년도 한국은행 경제직렬 필기 - (6) 통화 정책의 신용 경로 (0) | 2024.07.11 |
|---|---|
| 2024년도 한국은행 경제직렬 필기 - (5) 구매력 평가설 (1) | 2024.07.11 |
| 2024년도 한국은행 경제직렬 필기 - (4) 루카스 비판 (0) | 2024.07.09 |
| 2024년도 한국은행 경제직렬 필기 - (3) 허구적 회귀, 단위근 검정, 공적분 검정 (0) | 2024.07.09 |
| 2024년도 한국은행 경제직렬 필기 - (2) 라스파이레스 수량 지수, 파셰 수량 지수 (0) | 2024.07.09 |
한국은행 들어갈 때까지만 합니다
조만간 티비에서 봅시다



