

다음으로 데이터들을 불러와야 한다.

pd.read_csv()
위 함수를 사용하면 해당 경로에 있는 CSV 파일을 읽을 수 있다. CSV 파일은 "Comma-Separated Values"의 약자로 말 그대로 쉼표로 구분된 값들을 가진 파일 형식이다.

이런 식으로 헤더와 데이터 행으로 구성되어 있다.

원본 데이터는 예쁘지 않으니까 preprocess를 해야 한다. (데이터 정리 및 형식 통일, 노이즈 제거, 스케일 일치시키기 등을 한다.)
df = df.copy()
위 코드를 통해 원래 데이터를 deep copy로 복사해 온다.
def normalize_name(x):
return "-".join([v.strip(",().\"'") for v in x.split(" ")])
def ticket_number(x):
return x.split(" ")[-1]
def ticket_item(x):
items = x.split(" ")
if len(items) == 1:
return "NONE"
return "-".join(items[0:-1])
normalize_name(x)부터 살펴보면, 먼저 x.split(" ")를 통해 띄어쓰기로 구분된 애들을 분리한다.
그리고 v.strip(",().'"'")를 통해 분리된 애들의 양끝에 있는 특수문자들을 제거한다.
마지막으로 "-".join()를 통해 잘 정제된 애들을 하이픈(-)으로 묶는다.

ticket_number(x)는 티켓 이름의 뒤에 있는 숫자를 분리한다.

ticket_item(x)는 티켓 이름 앞에 있는 (숫자를 제외한) 애들만 분리한다.
df['Name'] = df['Name'].apply(normalize_name)
df['Ticket_number'] = df['Ticket'].apply(ticket_number)
df['Ticket_item'] = df['Ticket'].apply(ticket_item)
return df
그렇게 잘 처리된 애들을 df의 열에 반영하고 df를 return하는 것이 preprocess 함수의 목적이다.
preprocessed_train_df = preprocess(train_df)
preprocessed_serving_df = preprocess(serving_df)
preprocessed_train_df.head(5)
train.csv와 test.csv(serving으로 표현)에 적용하면 데이터 전처리가 끝난다.

input_features를 만들려면 이 columns 중에서 이렇게 세 가지를 빼야 한다.

Ticket은 글자와 숫자로 나눴으며, PassengerId는 생존을 예측하는 데 아무 필요가 없으며(아래 Ticket_number도 기껏 만들어 놓았더니 지우려고 하는 이유는 크게 쓸데가 없기 때문이다), Survived는 Input Features가 아니라 Target Variable이기 때문에 분리해야 한다.
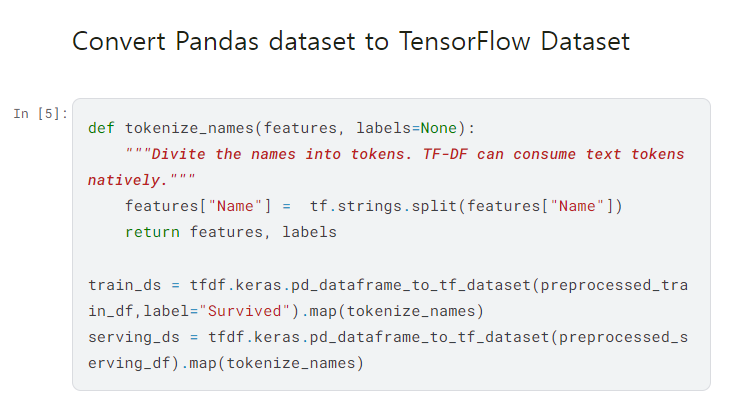
tokenize_names() 함수를 만든 이유는, 텍스트를 ML 모델에 적합한 형식으로 바꾸기 위해서다.
def tokenize_names(features, labels=None):
"""Divide the names into tokens. TF-DF can consume text tokens natively."""
features["Name"] = tf.strings.split(features["Name"])
return features, labels
토큰은 단어와 다르다. 텍스트를 그냥 띄어쓰기로 나누는 것이 단어라면 토큰화는 모델이 이해하고 처리하기 쉬운 형식으로 나누는 것이다. 영어 예시에서는 그게 그거 같은데 킹갓세종대왕님의 한글의 경우에는 토큰화를 했을 때 그 차이가 두드러진다.

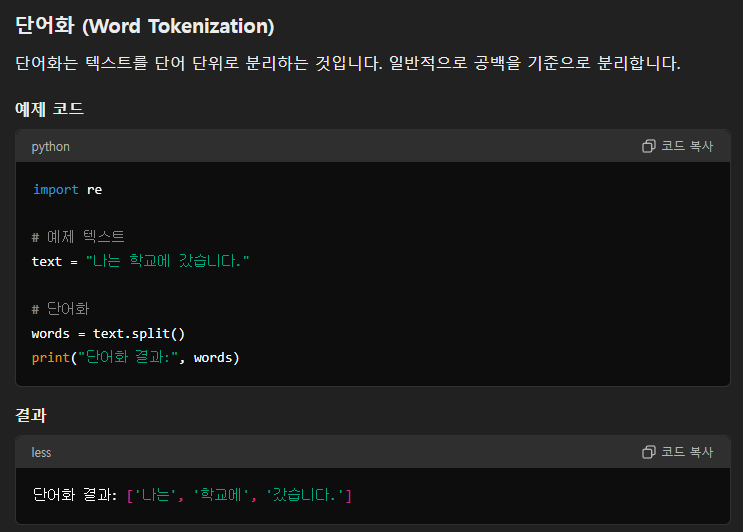
단어화는 아주 평범하다.
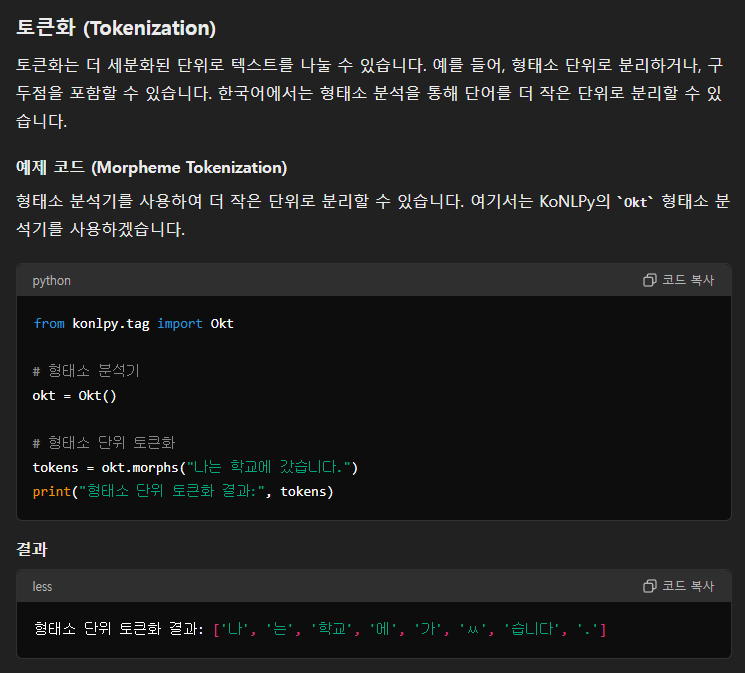
반면에 토큰화는 형태소 단위로 분리하거나 아무튼 뭔가 더 의미가 있는 식으로 분리를 한다.
def tokenize_names(features, labels=None):
"""Divite the names into tokens. TF-DF can consume text tokens natively."""
features["Name"] = tf.strings.split(features["Name"])
return features, labels
뭐 그건 그렇고 막상 코드에서는 그냥 공백을 기준으로 나눈 것으로 토큰화를 실시했다.
train_ds = tfdf.keras.pd_dataframe_to_tf_dataset(preprocessed_train_df, label="Survived").map(tokenize_names)
serving_ds = tfdf.keras.pd_dataframe_to_tf_dataset(preprocessed_serving_df).map(tokenize_names)
train_df와 serving_df를 TensorFlow 데이터셋으로 변환하기 위해 위의 함수를 사용했다. train_df를 넘겨줄 때는 label="survived"를 포함해서 이 항목이 target variable인 것을 알려줬다. 그리고 끝에 .map(toeknize_names)를 통해 각 셀에 대해 토큰화를 실시한다.
다음 글에서는 본격적으로 모델을 학습시키자!
'분명 전산학부 졸업 했는데 코딩 개못하는 조준호 > AI, ML, DL' 카테고리의 다른 글
| Kaggle Competition - Binary Prediction of Poisonous Mushrooms (1) EDA 전까지 (1) | 2024.09.02 |
|---|---|
| 역시 ML의 시작은 타이타닉 - (5) hyperparameter 튜닝 (8) | 2024.07.24 |
| 역시 ML의 시작은 타이타닉 - (4) GBT 모델 뜯어보기 (3) | 2024.07.20 |
| 역시 ML의 시작은 타이타닉 - (3) 모델 만들고 학습시키고 평가하기 (7) | 2024.07.20 |
| 역시 ML의 시작은 타이타닉 - (1) Dependencies 가져오기 (0) | 2024.07.20 |
한국은행 들어갈 때까지만 합니다
조만간 티비에서 봅시다



