

이제 모델을 만들고 학습해야 한다.

model = tfdf.keras.GradientBoostedTreesModel()
이 코드를 통해 TensorFlow Decision Forests (TF-DF) 라이브러리를 사용해 Gradient Boosted Trees 모델을 만든다. 함수 내부의 parameter를 보자.
verbose=0
verbose는 "장황한"이라는 뜻이다. 이 값이 0이면 훈련 과정 중 출력이 거의 없다. 기본값은 1로 에포크당 loss나 accuracy 등의 요약 정보를 출력한다. 1보다 커질 수도 있는데 커지면 커질수록 더 자세한 정보를 제공한다.
features=[tfdf.keras.FeatureUsage(name=n) for n in input_features]
사용할 features를 지정한다. 이전 글에서 데이터 preprocess를 할 때 학습에 사용할 친구들만 모아서 "input_features"를 만들었으니 얘네들을 차곡차곡 넣어주는 것이다.
exclude_non_specified_features=True
지정한 features 외의 features는 학습에 사용되지 않는다.
random_seed=1234
랜덤 시드.
이렇게 다 만들었으면 학습을 시키면 된다!
model.fit(train_ds)
모델을 만들고 학습까지 끝났으면 평가를 해야 한다.
self_evaluation = model.make_inspector().evaluation()
print(f"Accuracy: {self_evaluation.accuracy} Loss: {self_evaluation.loss}")
make_inspector()는 모델을 검사 및 평가하는 도구를 return한다. evaluation()는 평가 결과를 반환한다.
결과를 출력하고 확인하면 된다!
위의 모델에서는 Accuracy가 0.826, Loss가 0.861이 나왔다.
82.6%의 정확도로 예측을 한 것이다!
Loss가 높은지 낮은지는 케바케라서 일괄적으로 어떻다 말할 수는 없다. 암튼 낮을수록 좋다.
파라미터를 조금 더 다듬어서 모델을 만들 수도 있다.
위에서부터 쭉 주석처리된 애들까지 포함해서 뜯어보면 다음과 같다.
#compute_permutation_variable_importance=True
이게 True로 켜져 있으면 모델이 학습하는 도중 각 특징이 얼마나 중요도가 높은지 자동으로 평가한다.
#hyperparameter_template="benchmark_rank1@v1"
이 코드를 사용하면 TFDF 라이브러리에서 제공하는 하이퍼파라미터 설정을 불러올 수 있다. 미리 정의된 하이퍼파라미터 조합을 템플릿처럼 불러올 수 있는 것이다.
아래는 하이퍼파라미터와 그냥 파라미터의 차이.
#tuner=tuner
튜너를 사용하면 여러 하이퍼파라미터 조합 중에서 가장 좋은 애를 자동으로 찾아준다. (시간과 비용 때문에 필요하지 않으면 안 쓴다)
여기까지는 주석처리된 애들이었고,,
min_examples=1
min_examples는 decision tree에서 각 node가 분할되기 위해 필요한 최소 데이터 포인트(데이터 셋에서 각각의 행)의 수를 의미한다. 이 값이 너무 작으면 decision tree가 너무 깊어져서 over-fitting의 가능성이 있고, 너무 크면 복잡도가 낮아져서 보다 일반화된 예측을 할 수 있다.
잘 이해가 안 돼서 chatGPT를 괴롭혔더니 만족스러운 예시가 나왔다.

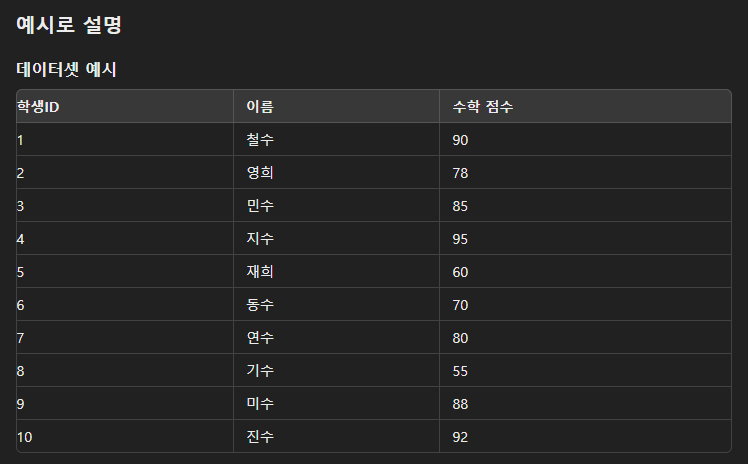


categorical_algorithm="RANDOM"
이 코드는 범주형 변수(값이 몇 가지 종류로 나뉘는 변수)를 처리하는 방식을 지정한다. 여러 방법이 있는데 이 중에서 RANDOM은 최적의 분할을 알아서 찾아준다.
#max_depth=4
트리의 최대 깊이를 지정한다. 트리가 너무 깊어지면 과적합이 생기기 때문에 이를 방지하기 위함이다.
위에 전체 코드 까먹었을까봐 다시 들고 옴.
shrinkage=0.05
이 코드는 학습률을 설정한다. 모델이 한 번의 학습 단계에서 얼마나 많이 조정될지를 결정한다. 그러니까 각 개별 트리의 기여도를 줄이는 데 사용된다.
값이 작을수록 천천히 학습하고 과적합이 방지된다. (각 단계에서 작은 변화만 일어나기 때문이다.)
값이 클수록 빠르게 학습하고 과적합의 위험이 커진다. (각 트리의 기여도가 너무 커서 노이즈까지 학습할 수 있기 때문이다.)
#num_candidate_attributes_ratio=0.2
트리 모델은 데이터를 분할할 때 여러 속성 중에서 최적의 속성을 선택하는데 위 코드를 쓰면 전체 속성 중에서 일정 비율을 무작위로 선택하고 이 중에서 기준으로 삼을 속성을 선택한다.
훈련 시간이 짧아지고, 랜덤이 들어가기 때문에 과적합을 방지한다.
split_axis="SPARSE_OBLIQUE"
트리를 분할할 축을 지정한다.

후자가 더 높은 성능, 더 많은 시간이라고 생각하고 넘어가자.
sparse_oblique_normalization="MIN_MAX"
각 속성의 정규화 방식을 지정하는 파라미터다. MIN_MAX를 사용하면 범위를 0과 1 사이로 맞춰준다.

sparse_oblique_num_projections_exponent=2.0
여러 특성을 결합하여 만든 새로운 특성은 데이터의 숨겨진 구조를 더 잘 파악할 수 있다.
해당 코드에서 숫자가 클수록 projection의 수가 커지며 더 복잡해진다.
num_trees=2000
이건 쉽다. 모델에서 사용할 트리의 수를 지정한다. 클수록 성능이 좋아지고 훈련 시간이 오래 걸린다.
#validation_ratio=0.0
데이터 셋을 train과 validation으로 나누는 비율을 지정한다. 이 값이 0.1이면 10%가 validation으로 사용된다.
validation은 과적합을 방지하고 하이퍼파라미터를 조정하고 성능을 확인하기 위해 사용한다.
보통 training dataset : validation dataset : test dataset = 60~80 : 10~20 : 10~20의 비율로 사용한다.
random_seed=1234
또 랜덤 시드다. 얘가 동일하면 재현성을 보장하고, 서로 다른 설정에서 얻어진 모델을 비교할 때 일관성을 유지할 수 있다.
이제 끝났다!
mode.fit(train_ds)를 하면 된다.
어라랑 근데 Accuracy와 Loss가 이전보다 더 낮게 나왔다!!! 분명 improved라고 했는데 말이지,,
'분명 전산학부 졸업 했는데 코딩 개못하는 조준호 > AI, ML, DL' 카테고리의 다른 글
| Kaggle Competition - Binary Prediction of Poisonous Mushrooms (1) EDA 전까지 (1) | 2024.09.02 |
|---|---|
| 역시 ML의 시작은 타이타닉 - (5) hyperparameter 튜닝 (8) | 2024.07.24 |
| 역시 ML의 시작은 타이타닉 - (4) GBT 모델 뜯어보기 (3) | 2024.07.20 |
| 역시 ML의 시작은 타이타닉 - (2) Preprocess 후 Tensorflow DataSet으로 전환 (0) | 2024.07.20 |
| 역시 ML의 시작은 타이타닉 - (1) Dependencies 가져오기 (0) | 2024.07.20 |
한국은행 들어갈 때까지만 합니다
조만간 티비에서 봅시다



